10. Specification of the HDF5 File Format#
10.1. General Conditions#
Data must be provided through an HDF5 file, structured as detailed below. When exporting an HDF5 file from NaxToPy, it will follow this same structure.
The HDF5 file distinguishes between two types of information: result data and metadata. Metadata can be either mandatory or optional. Although NaxToPy automatically fills them in during export, it is not required to include all of them when importing.
10.1.1. Conventions for Strings#
All string values in attributes and datasets must be stored as variable-length strings with UTF-8 encoding and NULL-terminated in HDF5:
HDF5 type:
String, length = variable,cset = H5T_CSET_UTF8,padding = H5T_STR_NULLTERM.Fixed-length strings are not allowed (avoid space-padding and truncation issues).
Applies to all textual attributes:
SOFTWARE,DESCRIPTION,SUBTITLE,TYPE,PART, etc.Reminder for
PART: its value is a string with the exact format(<int>, '<text>').

Fig. 1 Example of attributes DESCRIPTION and TYPE as String, length = variable, UTF-8, NULL-terminated.#
10.2. Root File Attributes /#
Attribute |
Value |
Description |
|---|---|---|
|
|
Indicates the software used to generate the file (NAXTO, NAXTOVIEW, NAXTOPY, etc.). |
|
Free text string (Optional) |
General description of the HDF5 file content. |
|
|
File creation date. |

Fig. 2 Attributes of the root file /#
10.3. Hierarchical Group Structure#
The HDF5 file follows a hierarchical structure composed of several groups:
10.3.1. Root Group /#
10.3.1.1. NAXTO Group#
Main data container. This group must exist and must be named exactly as shown.
Attribute |
Value |
Description |
|---|---|---|
|
|
Version of the exported HDF5 schema. |
|
|
Assembly version number. |

Fig. 3 Attributes of the NAXTO group.#
10.3.2. RESULTS Group#
This group must exist with this exact name. It contains the load cases.
10.3.2.1. Load Case Group X#
This group represents the results corresponding to load case X.
Attribute |
Value |
Description |
|---|---|---|
|
|
Generic description of the load case. |
|
X (Optional) |
Numerical identifier of the load case. |
|
|
Solution type (e.g., linear static, such as Nastran SOL101). |
|
|
Load case subtitle. |

Fig. 4 Attributes of the load case group X.#
10.3.2.2. Increments Y#
This group represents increment Y within the load case.
Attribute |
Value |
Description |
|---|---|---|
|
|
Free text. |
|
|
Increment number. |
|
|
Increment value (float, 32 bits). |

Fig. 5 Attributes of increment Y.#
10.3.2.3. Results RESULT_NAME#
This group represents a type of result within an increment.
Attribute |
Value |
Description |
|---|---|---|
|
Free text string (Optional) |
Result description. |
|
|
Type of result. |

Fig. 6 Attributes of result RESULT_NAME.#
Component Schema Consistency#
For any given RESULT_NAME, all child sections must expose datasets with an identical compound schema:
Same member names and order (e.g.,
ID ENTITY,XX,XY,YY,VON_MISES,MAX_PRINCIPAL,MIN_PRINCIPAL, andID NODEwhen applicable).Same base types and shapes (e.g.,
ID NODEmust beint[4]in all sections if present).Same floating-point precision for all component members (either all
float32or allfloat64).
Only the dataset row count and the dataset’s PART attribute may differ between sections. Files that violate this rule are invalid for that result.

Fig. 7 Example: under STRESS_NEUBER_1D, sections POINT_A and POINT_B contain datasets with the exact same set of components. Under STRESS_NEUBER_2D, sections Z1 and Z2 also match.#
10.3.2.4. SECCION1 Group#
This group represents a specific result section. There will be as many groups SECCION1, SECCION2, … as there are result sections.
Attribute |
Value |
Description |
|---|---|---|
|
Free text string (Optional) |
Description of the result set in this section. |

Fig. 8 Attributes of the SECCION1 group.#
10.4. Dataset: Name "PART_NAME"#
Inside each section group (e.g., SECCION1), there is a dataset with an arbitrary name, such as PART_NAME.
When creating the dataset, it’s important to ensure that the correct value for the number of dimensions is set to 1. If it is defined as 2, the reading code may fail or misinterpret the structure.

Fig. 9 Number of dimensions of the dataset.#
Attribute |
Value |
Description |
|---|---|---|
|
Free text string (Optional) |
Description of the data stored in the dataset. |
|
Free text string (Mandatory) |
The value must be provided exactly in the following format: a tuple with two elements enclosed in parentheses, where the first element is an integer and the second is a string that must be enclosed in single quotes. For example: (0, ‘Part_1_1’). It is essential to use the parentheses and single quotes exactly as indicated. Alternative formats, such as using square brackets, double quotes, or omitting the quotes, are not valid. |
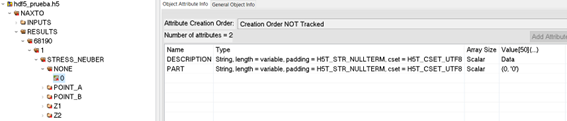
Fig. 10 Attributes of the dataset.#
Column |
Type |
Description |
|---|---|---|
|
integer (4 bytes) |
Element identification number. |
|
vector of 4 integers (4 bytes each) |
Associated node ID (only if |
|
scalar / 4 float vector (4 or 8 bytes) |
XX result component. |
|
scalar / 4 float vector (4 or 8 bytes) |
XY component. |
|
scalar / 4 float vector (4 or 8 bytes) |
YY component. |
|
scalar / 4 float vector (4 or 8 bytes) |
Von Mises stresses. |
|
scalar / 4 float vector (4 or 8 bytes) |
Maximum principal stress. |
|
scalar / 4 float vector (4 or 8 bytes) |
Minimum principal stress. |
Important Note — Floating precision: All the component values must have the same format, either all as 4-byte or all as 8-byte floats. Mixing formats will result in errors loading the model.
Important Note — Consistency across sections: Within a single RESULT_NAME, the compound schema of all section datasets must be identical (member names, order, types/shapes, and float size). Mixed schemas across sections are not allowed and will be rejected by readers.
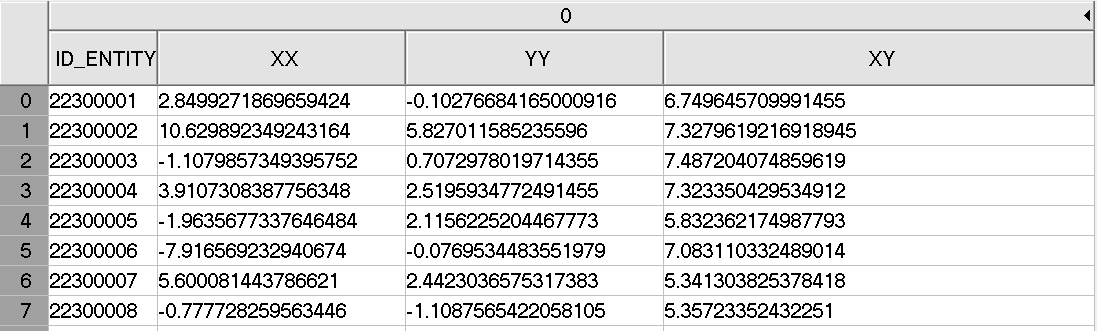
Fig. 11 Example of dataset PART_NAME.#
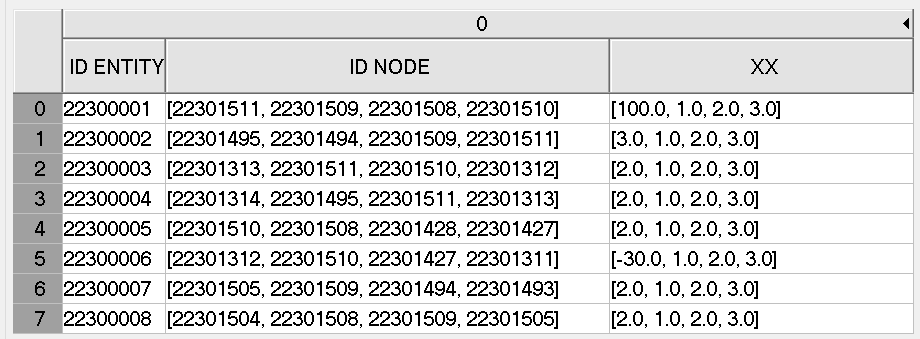
Fig. 12 Example of dataset PART_NAME - Element Nodal.#